并发控制算法与per-CPU数据成对出现,是确保底层库和高性能应用程序在当今硬件上正确扩展不可或缺的一部分。这些算法保证在并发访问时,用户空间的数据结构始终保持一致,并且用户数据的修改是执行完全的,使得线程观察到的是之前或之后的状态,而非中间状态。
设计这些算法的方法有很多种,最常见的也是扩展性最差的一种是mutex。它的工作原理是,在任何时间,只允许一个线程持有mutex并修改共享数据结构。
但是,mutex并不能很好地扩展,尤其是对于per-CPU数据而言。由于在mutex加锁和解锁的临界区内只能有一个线程可访问,因此可能存在大量线程在等待锁,而等待的时间内线程没有做任何有用的事。
接下来的可扩展并发控制算法是,原子比较和交换。在这个模型中,通常使用单个指令进行同步控制,例如cmpxchg指令或x86体系结构的指令lock前缀。
但这里的问题是,在现代处理器上原子指令代价很高,相比于没有前缀的相同指令,x86的lock前缀很容易在执行成本上增加多个指令周期。更糟糕的是,无论是否只有一个线程在竞争,lock前缀都会无条件执行。
并且,并不是所有体系结构都为原子数据更新提供单独的指令。例如,ARM使用link-load/store-conditional(简称LL/SC)组合指令来读取原始数据、修改原始数据并写入新数据,如果两个线程同时尝试写入,只有一个线程将会成功,另一个线程失败并重启LL/SC指令序列。
Linux内核使用其他方法来保护per-CPU数据,例如禁用抢占或中断,或使用per-CPU本地的原子操作。遗憾的是,这些方法要么不易被用户空间使用,要么相对较慢(例如原子指令)。所以,我们需要一种轻量型的机制,用于在用户空间内保护per-CPU数据,这就是restartable sequences方法(rseq)的产生的动机。
rseq是如何工作的
rseq由新的系统调用rseq(2)所组成,该调用告诉内核当前线程rseq相关的thread-local ABI(sturct rseq对象)在内存中的位置。sturct rseq对象包含一个rseq_cs类型字段,该字段是指向当前被激活的rseq临界区的描述符(sturct rseq_cs对象)的指针,而在任何时候,只能有一个临界区被激活。此ABI有两个用途:用户空间的rseq和快速读取当前CPU编号。
临界区可细分为准备阶段(preparatory stage)和提交阶段(commit stages),其中提交阶段是仅是单条CPU指令。如果在提交阶段之前发生以下任何情况之一,则认为当前临界区被中断:
- 线程已迁移到另一个CPU上
- 信号(signal)被传递到该线程
- 线程被抢占
此外,由于线程被中断时需要回退机制,内核将程序寄存器(instruction pointer)指向中断处理程序的首地址,该处理程序需要执行一些纠正性的措施,例如重新发起准备阶段。在这样的设计下,乐观情况下(线程未被中断)执行速度非常快,因为开销较高的struct rseq_cs的上锁和原子指令可完全避免。
更详细地说,当前rseq临界区是由struct rseq_cs对象所描述,该对象被struct rseq对象所引用。下面用如下的图来说明它们的关系和结构体的字段。
")
rseq的开始和结束由start_ip和post_commit_ip(指向提交阶段后的首地址指令)所表示,而abort_ip指向中断处理程序的首地址指令。
值得注意的是,临界区和中断处理程序的实现都有所限制。例如,中止处理程序必须处于临界区以外,以及在临界区内不允许有系统调用,尝试执行系统调用将导致进程发生segmentation fault而终止。
每当线程迁移到其他CPU上执行,且在用户空间程序临界区的开始处读取cpu_id_start并比较这两个值时,内核就会更新cpu_id字段。如果它们的值不同,则正在运行的线程将被中断,且需要重新尝试rseq序列。
内核和用户空间均可修改rseq_cs字段。当启动rseq时,用户空间代码需要将指针设置为当前临界区的描述符。每当在执行当前rseq_cs描述符所描述的临界区范围之外的代码时,或发生抢断或传递信号时,就会将该指针设置为NULL。
rseq的简史
Linux在4.18内核版本中合并了对rseq的支持。作为一种无需锁或开销较高的原子指令,即可从用户空间数据中安全访问per-CPU数据的方法,restartable sequences的概念最初是由Paul Turner和Andrew Hunter在2013年所提出,但在当时还没有可用的patch。
两年后,为了促使他们将其补丁发布到Linux kernel的mailing list中,Mathieu Desnoyers于2015年5月提交了针对per-CPU临界区的patch。一个月后,Paul发布了rseq的第一个patch集合。虽然Paul在发布该版本之后便停了下来,Mathieu于2016年又重新接手,提交了新的patch集合,并在LPC 2016上介绍了这一工作。他原本希望将patch合并到Linux内核的4.15版本中,但发现存在如下的障碍:
虽然几乎每个版本的patch集都有benchmark数据,但Linus明确表示,这种假设的用例不足以合并rseq的相关功能,并需要具体的性能数据作为支撑。
后来,Facebook提供了在jemalloc内存分配器上使用patch的数据结果。因此,Mathieu收集了更多类似的benchmark结果,并在其他项目(如LTTng-UST、Userspace RCU和glibc)上提供了rseq的支持。
最终,在最初开始的五年之后,该patch集终于被合并到Linux内核中,Mathieu在Open Source Summit Europe 2018上作了名为Improve Linux User-Space Core Libraries with Restartable Sequences的演讲,其中介绍了将rseq带入Linux的多年努力。
如何在库和程序中使用rseq
使用rseq的首选方法是使用librseq,该库提供了可能会用到的所有per-CPU操作,例如使rseq(2)调用对当前线程可用(rseq_register_current_thread()),查询当前线程的CPU编号(rseq_current_cpu()),以及更新per-CPU数据(rseq_cmpeqv_storev())。
但如果要实现自己需要的特定操作,请继续阅读以获得更详细的说明。
使用rseq(2)需要以下两步。首先,使用rseq(2)为当前线程启用该功能,该系统调用具有以下的函数原型:
1 | sys_rseq(struct rseq *rseq, uint32_t rseq_len, int flags, uint32_t sig) |
该系统调用的目的是向内核注册struct rseq对象,其中flags参数为0表示注册,rseq_FLAG_UNREGISTER表示注销。sig参数是可用于验证rseq上下文的签名,也就是说,用于注册的签名必须与用于注销的签名相同。
比如说,你想使用rseq(2)来增加per-CPU计数器的值,为此,需要获取当前线程的CPU编号(存储在struct rseq的cpu_id_start字段中),并使用rseq修改per-CPU计数器的值。因此,需要通过C和汇编混写的代码实现,下面是完成该操作的代码。
1 |
|
rseq_addv()中的代码以struct rseq_cs对象填充作为开始,该对象描述了rseq中的字段,其中start的label为1,post-commit为2,中断处理程序为4。如果线程未完成1和2之间的序列,那么将直接控制跳转到标签4,然后跳转到C中的abort位置处。
注意:必须确保CPU编号只读取一次,在编译器层面需要强制使用volatile关键字来保证这一点,而在上面的例子中,rseq_ACCESS_ONCE()宏对此提供了保证。
rseq到底有多快?
rseq的主要使用场景之一是获取执行当前线程的CPU编号,通常也就是指向per-CPU数据结构的索引值。当前使用sched_getcpu()来获取CPU编号的方法,在ARM上需进行系统调用,在 x86上需调用VDSO,而rseq(2)则允许程序直接读取内核和用户空间之间共享的struct rseq对象中缓存的CPU编号值。
在该场景下,rseq在X86平台可获得20倍加速,而在ARM平台上则是35倍加速。
下图展示了获取执行当前线程的CPU编号的rseq方法的速度提升,值越小越好,其反映了速度的提升。
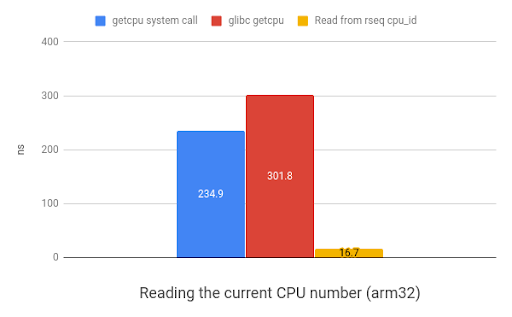 |
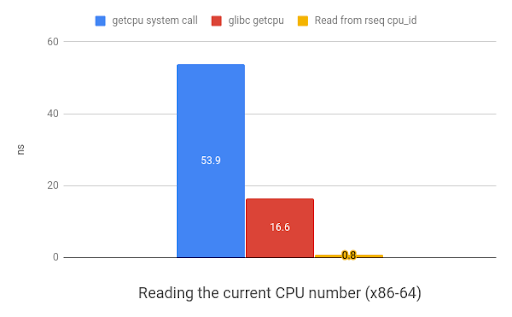 |
|---|---|
| 在arm32上读取当前CPU编号benchmark(来自于 www.efficios.com) | 在x86_64上读取当前CPU编号benchmark(来自于 www.efficios.com) |
如上所述,rseq也适用于其他多种使用per-CPU数据的场景,其中之一是存储计数器值。下图展示了使用rseq(2)增加per-CPU计数器时,相对于使用sched_getcpu()和原子指令的速度提升。在ARM平台上显示有11倍的提升,而在x86显示是7.7倍提升。
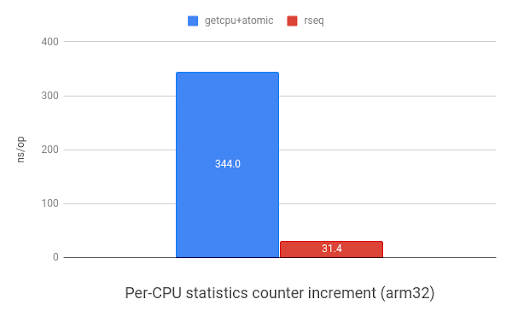 |
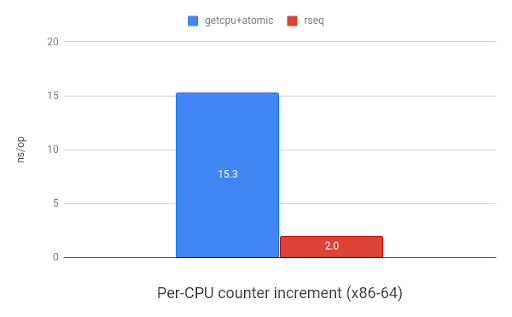 |
|---|---|
| 在arm32上统计增加计数器benchmark(来自于 www.efficios.com) | 在x86_64上统计增加计数器benchmark(来自于 www.efficios.com) |
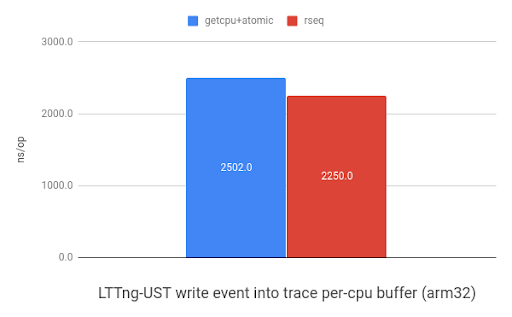
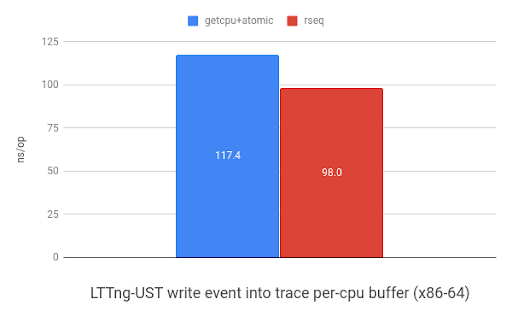
LTTng-UST使用per-CPU的buffer来存储event。下图展示了使用rseq(2)在per-CPU缓存中存储32位header和event时,相对于使用sched_getcpu()和原子指令的速度提升。在ARM平台上显示有1.1x的提升,而在x86显示是1.2x提升。
 |
 |
|---|---|
| 在arm32的LTTng-UST上将event写入per-CPU缓存的benchmark(来自于 www.efficios.com) | 在x86_64的LTTng-UST上将event写入per-CPU缓存的benchmark(来自于 www.efficios.com) |
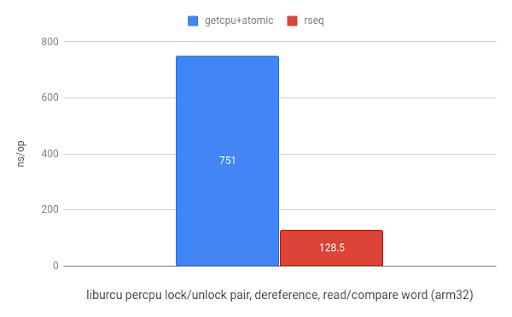
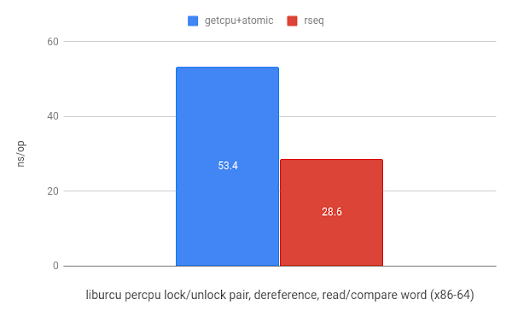
最后,在Userspace RCU项目中,在liburcu库中使用rseq后,在ARM有5.8倍加速,而在x86上有1.9倍加速。
 |
 |
|---|---|
| 在arm32的liburcu的per-CPU上加/解锁,解引用读/比较的benchmark(来自 于www.efficios.com) | 在x86_64的liburcu的per-CPU上加/解锁,解引用读/比较的benchmark(来自于www.efficios.com) |
下一步计划
虽然使用rseq(2)的patch适用于LTTng、Userspace RCU和glibc,但它们现在仅处于概念验证阶段。下一阶段的工作,则是将它们合并到各自项目的代码中。对于glibc而言,这意味着patch在线程开始时自动通过rseq(2)注册,在线程退出,以及主线程的NPTL初始化时自动注销。
LTTng-UST的问题有点不同:不更改线程的affinity mask,就无法在per-CPU数据结构之间移动数据。为了解决这个问题,Mathieu提出了一个新的cpu_opv系统调用,类似readv(2)和writev(2)的struct iovec概念,该调用在特定CPU上执行固定向量操作(比较、memcpy 和add)。cpu_opv解决的rseq(2)的另一个问题是,如果单步执行到临界区,调试器将死循环。即使库使用了rseq(2),新的cpu_opv系统调用也允许调试器与现有应用程序共存。
Mathieu最初希望能及时将新的cpu_opv系统调用合并到Linux内核的4.21版本,但Linus Torvalds已经表示,他希望看到rseq(2)的使用者首先出现,这意味着glibc需要合并那些正在进行的rseq(2)的patch工作。
(译者注:本文原地址为 https://www.efficios.com/blog/2019/02/08/linux-restartable-sequences/)